|
I am a reserach engineer at Meta. I work on developing new methods for efficient AI models. I recieved my PhD from Ecole Polytechnique Montreal in electrical engineering. Email / Google Scholar / Github / Linkedin |

|
 |

In this project, we investigate the generalization properties of quantized neural networks. We develop a theoretical model demonstrating how quantization functions as regularization and derive an approximate bound for generalization conditioned on quantization noise. To measure generalization, we used proxy measures such as sharpness and validated our hypothesis through experiments on over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets, covering both convolutional and transformer-based models. |
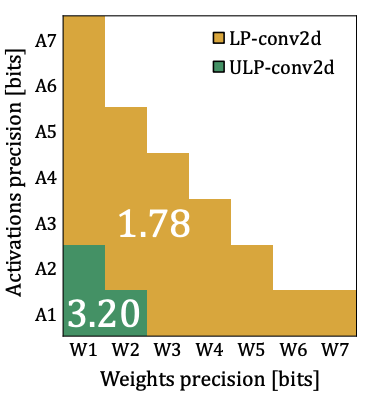 |
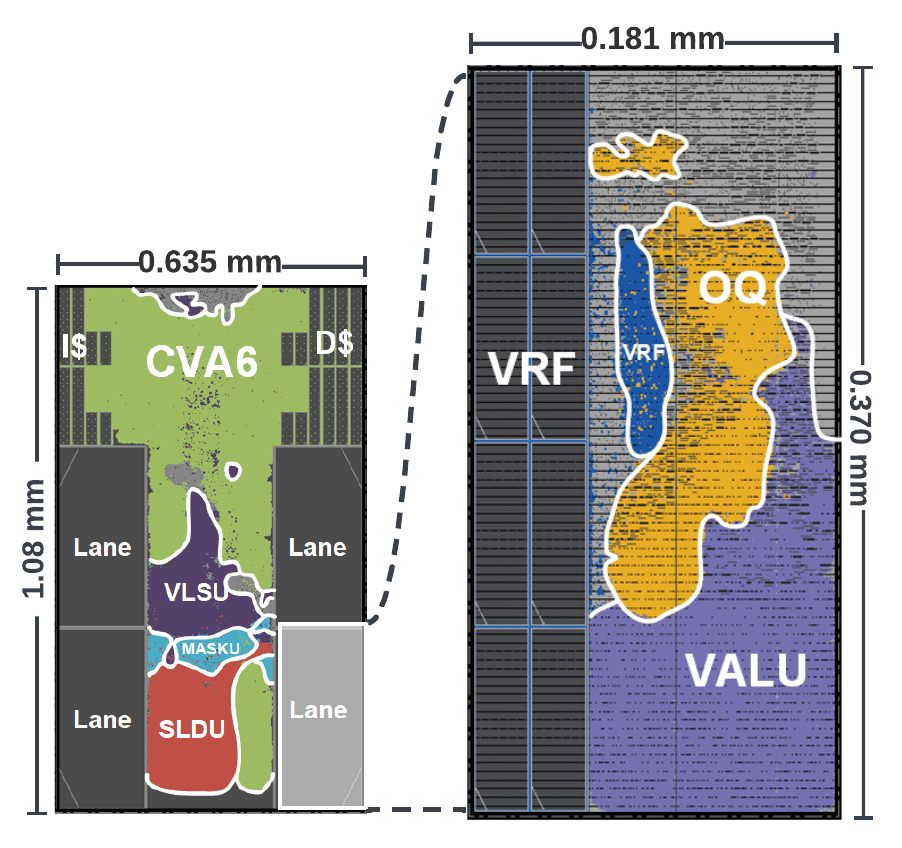
Implemented in GF 22 FDX, Sparq is an RISC-V vector processor that is designed to perform sub-byte computation for Quantized Neural Network inference. It outperforms Quark in 2-4 bit region. |
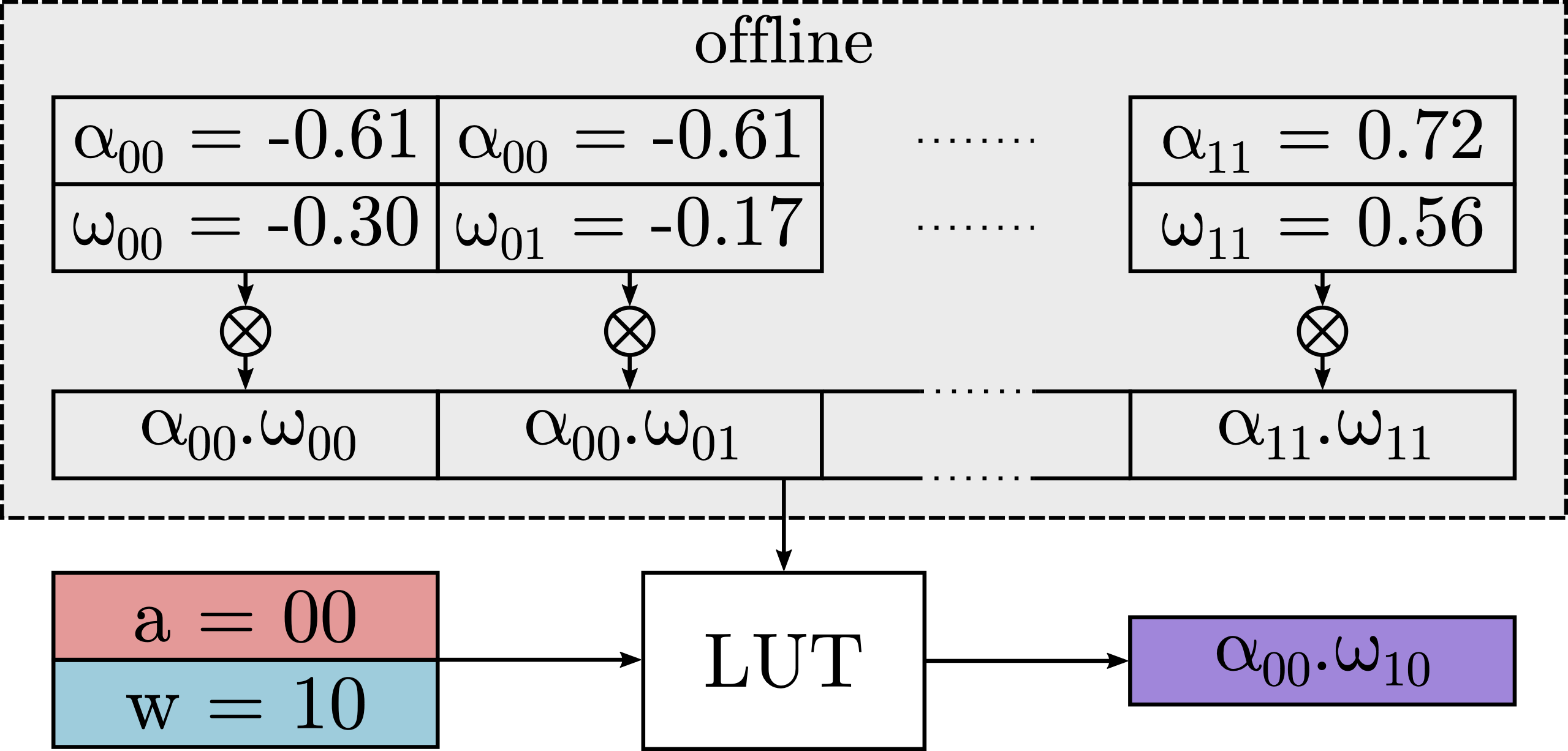 |
DeepGEMM is a lookup table based approach. It efficiently executes ultra low-precision convolutional neural networks on x86 platform. DeepGEMM outperforms 8-bit integer kernels in the QNNPACK framework. |
 |
 /
/
Implemented in GF 22 FDX, Quark is an integer RISC-V vector processor that is designed to perform sub-byte computation for Quantized Neural Network inference. |
|
/
In need of an arbitrary precision DNN accelerator? Checkout BARVINN! an open source FPGA DNN accelerator. |
 |
Performing Ultra-Low bit inference computation on ARM CPUs. This paper provides 2 bit model running on commodity hardware. Mixed precision approach was used to minimize the accuracy loss. Novel method is proposed to run the 2 bit models on Arm Cortex A devices. Benchmark on classification and Object detection models are presented. |
 |
/
 /
/

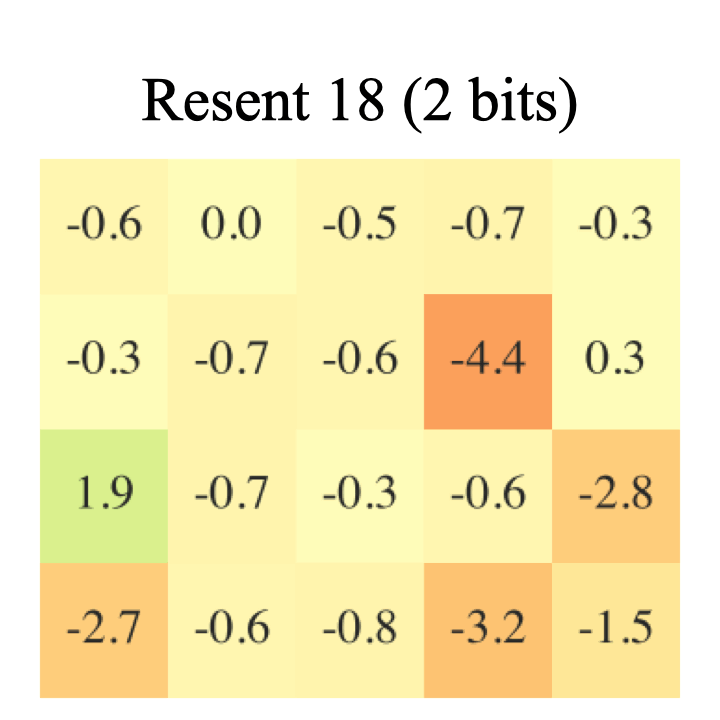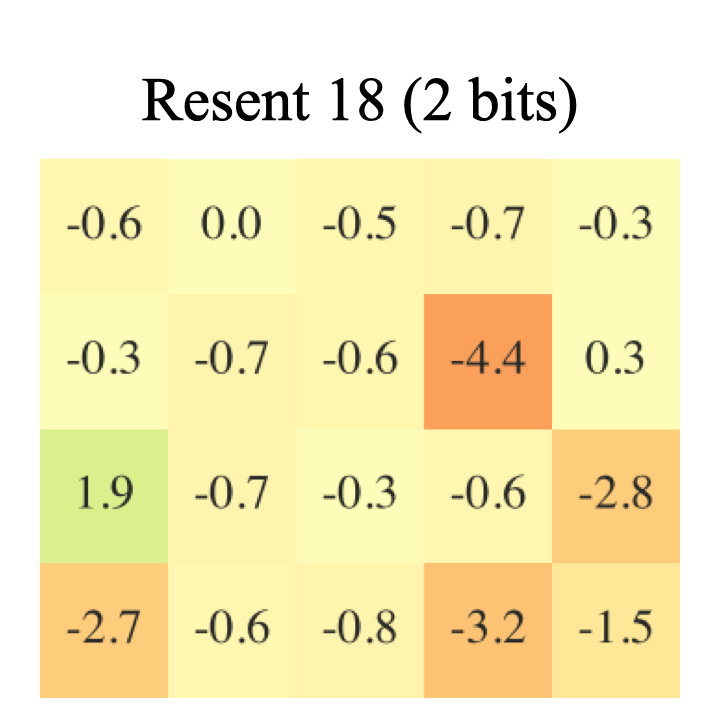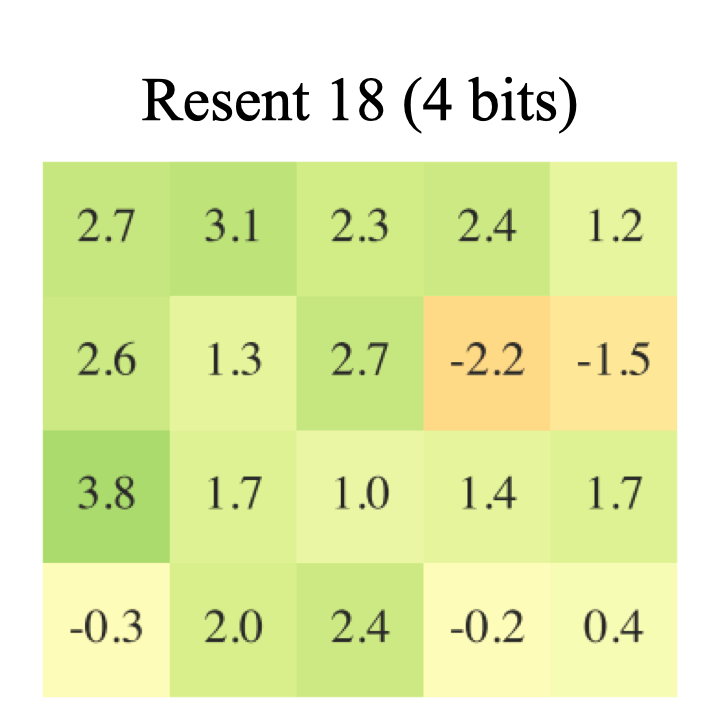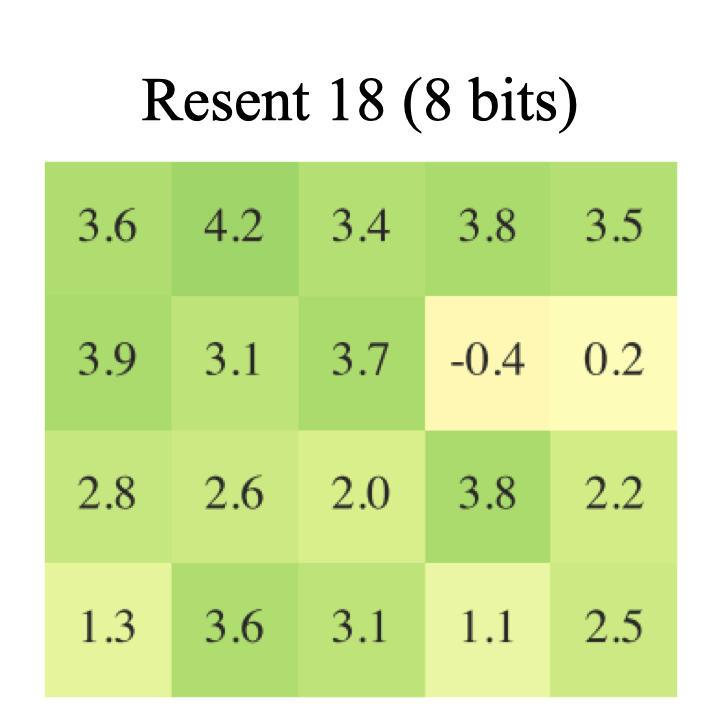
In this paper, we explored how quantization effects training. More specifically, we study the regularization effect of quantization. We show that regardless of dataset, model, quantization level and technique, 8-bit quantization is a reliable source of regularization. |
 |
 /
/
Based on the architecture proposed in our FCCM 2020 paper, we built a RISC-V core that is connected to a neural network accelerator capable of performing Matrix Vector product. We used this system to compute a GEMV operation with an input matrix size of 8 by 128 and a weight matrix size of 128 by 128 with two-bit precision in only 16 clock cycles. |
 |
Won IAAI Deployed Application Award!  /
/
In this work, we introduce a black-box framework, Deeplite Neutrino^{TM} for production-ready optimization of deep learning models. The framework provides an easy mechanism for the end-users to provide constraints such as a tolerable drop in accuracy or target size of the optimized models, to guide the whole optimization process |
 |
/
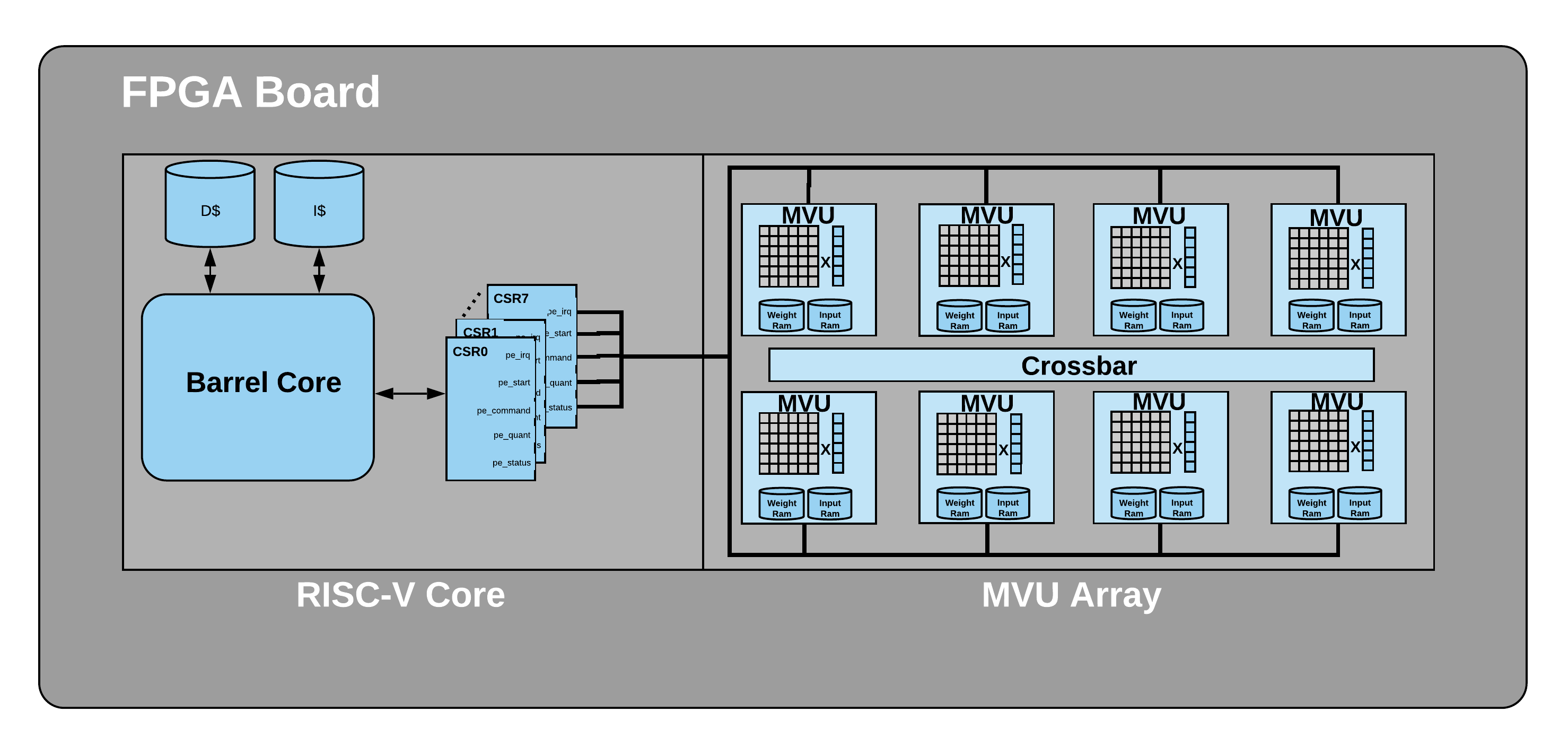
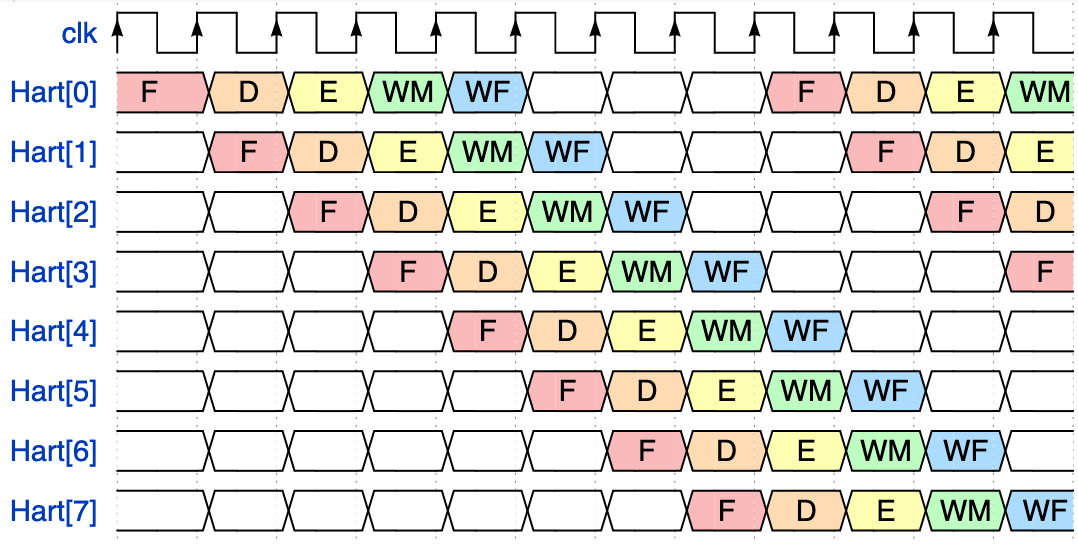
In this paper we designed a Barrel RISC-V processor. We used 8 harts (hardware threads) to control 8 Matrix Vector Units for a Deep Neural Network application. We have implemented our design on a Xilinx Ultrascale FPGA. Our 8-hart barrel processor runs at 350 MHz with CPI of 1 and consumes 0.287W. |
|
/
/
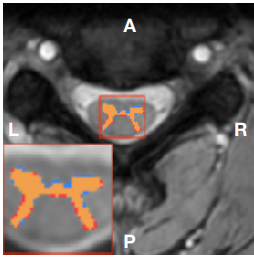
In this work, we present a fixed point quantization method for the U-Net architecture, a popular model in medical image segmentation. We then applied our quantization algorithm to three different datasets and comapred our results with the existing work. Our quantization method is more flexible (different quantization level is possible) compared to existing work. |
|
|
 /
/

In this presentation, I talked about BARVINN, a Barrel RISC-V Neural Network Accelerator. |
|
|
/
In this presentation, I talked about how to accelerate computation in Deep Neural Networks. Specifically, I talked about Quantization. Quantization in Deep Learning is a technique to reduce power, memory and computation time of deep neural networks. I talked about how one can improve the performance of a DNN using both software and hardware solutions. |

|
/
In this workshop, I reviewed the most popular open source tools for design and simulation of digital systems. The attendants got a chance to use these tools and developed a simple circuit to calculate GCD. In the second part of the workshop, I talked about RISC-V and Chisel. At the end of the workshop, the attendants got a chance to use chisel to designa and simulate a 3-stage pipelined RISC-V core. |
|
|